

The Data Lakehouse architecture is an extremely well-performing technology that supports direct access data types, has first-level support for machine learning and data science but before talking more about Data Lakehouse architecture, we would like to briefly describe the structures used today with their advantages and disadvantages.
The structure that most companies actively use today consists of a structure in which the first generation data analysis platform, Data Warehouse, or the second generation data analysis platform, Data Lake and in some cases Data Warehouse and Data Lake are used together, depending on the needs of the company and the data they hold.
First Generation Data Analytics Platforms
Businesses using Data Warehouse first faced the situation that became very costly as their datasets grew. It was followed by the lack of support for video, audio, text, data science and machine learning in data warehouses. Also there is limited support for streaming in Data Warehouses. As a solution to these problems second-generation data analytics platforms, which we call data lakes, have emerged.
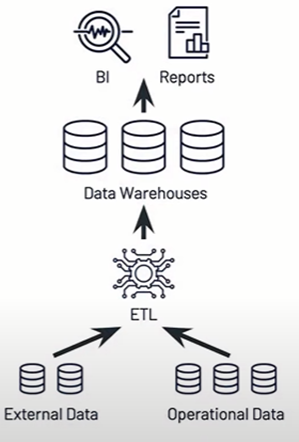
(Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics
Authors: Michael Armbrust, Ali Ghodsi, Reynold Xin, Matei Zaharia)
Second Generation Data Analytics Platforms
Data lakes can manage all data for data science and machine learning, which we lack in data warehouses, but Data lake structure has ;
1. Low Business Intelligence support
2. Complex to set up
3. Poor performance
4. Poor data quality control
As a result most enterprises extract data from their data lakes to data warehouse for Business Intelligence and Analytics use cases.
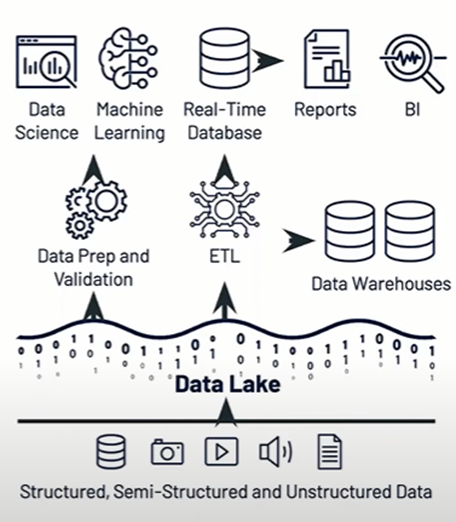
(Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics
Authors: Michael Armbrust, Ali Ghodsi, Reynold Xin, Matei Zaharia)
What Are Today's Data Architecture Challenges and How Does Data Lakehouse Solve Them?
Generally, Data Lakes have data in semi-structured format, as a result, operations have difficulty delivering features such as downgrade and zero-copy cloning.
However, newer systems like Delta Lake and Apache Iceberg make Data Lake appear transactional and enable these features. Creating datasets within the Lakehouse requires writing ELT/ETL logic and doing the same work, but there are fewer ETL steps overall and analysts can query raw data tables with performance if they want to.
Many ML systems have adopted the DataFrame structure. Declarative APIs were designed to perform query optimizations for data access in ML workloads in current systems. These APIs can directly benefit from many optimizations in the Lakehouse build. Organizations today collect a large amount of unstructured images, sensor data, and documents. Organizations need easy-to-use systems to manage this data, but Data Warehouses and APIs does not support this.
There are several techniques for Lakehouse architecture to provide cutting-edge SQL performance on massive Parquet datasets and to optimize data layout within available formats.
As a result, many customers state that they are not satisfied with the Datalake + Warehouse model. First, the major Data Warehouses added support for Parquet and external tables in ORC format. As a result, DWH users became able to query Datalake with SQL, but it did not solve the problems we encountered in this structure, such as ETL complexity, obsolescence, advanced analytical difficulties. Also, SQL often performs poorly because it is optimized for its internal data structure.
Advantages of Data Lakehouse
- First of all, one of the most important advantages of Data Lakehouse is that it is a single platform for every business, a single Data Lakehouse is sufficient for both Business Intelligence and Machine Learning.
- Data Lakehouse has a high performance query engine called Delta Engine.
- Data Lakehouse has a Structured transaction layer.- Data Lakehouse has Delta Lake layer for all data types.
- Thanks to the open format parquet, ACID (Atomicity, Consistency, Insulation and Durability) operations can be performed.
- Batch and Streaming data processes are supported.
- Data Lakehouse is 100% compatible with Apache Spark.
- It is possible to go back in time with Delta Lake. It is also known as the version system. All changes made to the tables are kept in an atomic change log, thanks to this log we can return to any structure we have created in the past. Thanks to the version system, we get rid of irreversible changes, it provides advantages in terms of data control and data management.
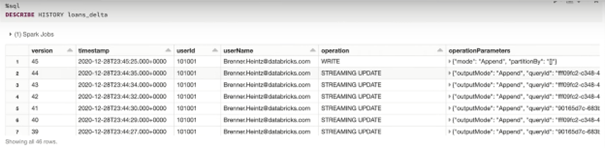
- Data Lakehouse has full DML support (Delete, Update, Merge Into)
- We can restore deleted or changed data using a version.
- Delta Lake supports upsert commands.
Conclusion
Above, we talked about the data architectures used today and the Data Lakehouse architecture, which emerged as a solution to the challenges we face in these architectures. If you want to combine the data science and machine learning support provided by the data lake and the business intelligence and reporting support provided by the data warehouse and have all of them in a single structure, you should consider switching to the Data Lakehouse architecture.
For more information, you can explore Trendify's solutions and contact us.
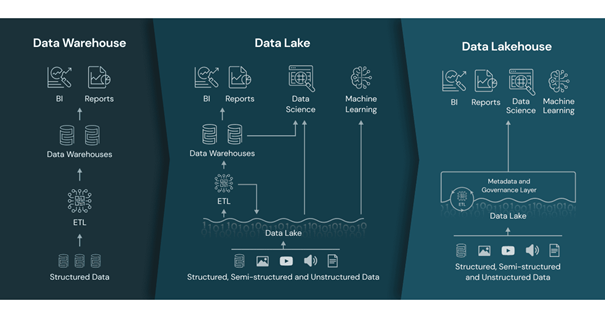
(www.databricks.com)
