

The importance of data and reporting in today's world is known, in this article we will look more at the concept of data warehouse, which facilitates data reporting and provides us with a lot of convenience in terms of data.
What is a Data Warehouse?
A data warehouse is a very large virtual warehouse that contains data rather than physical products. It is important to remember that even if a data warehouse has a similar name, it is not the same as a database. But there is a relationship between them, usually the data warehouse is built on some kind of database.
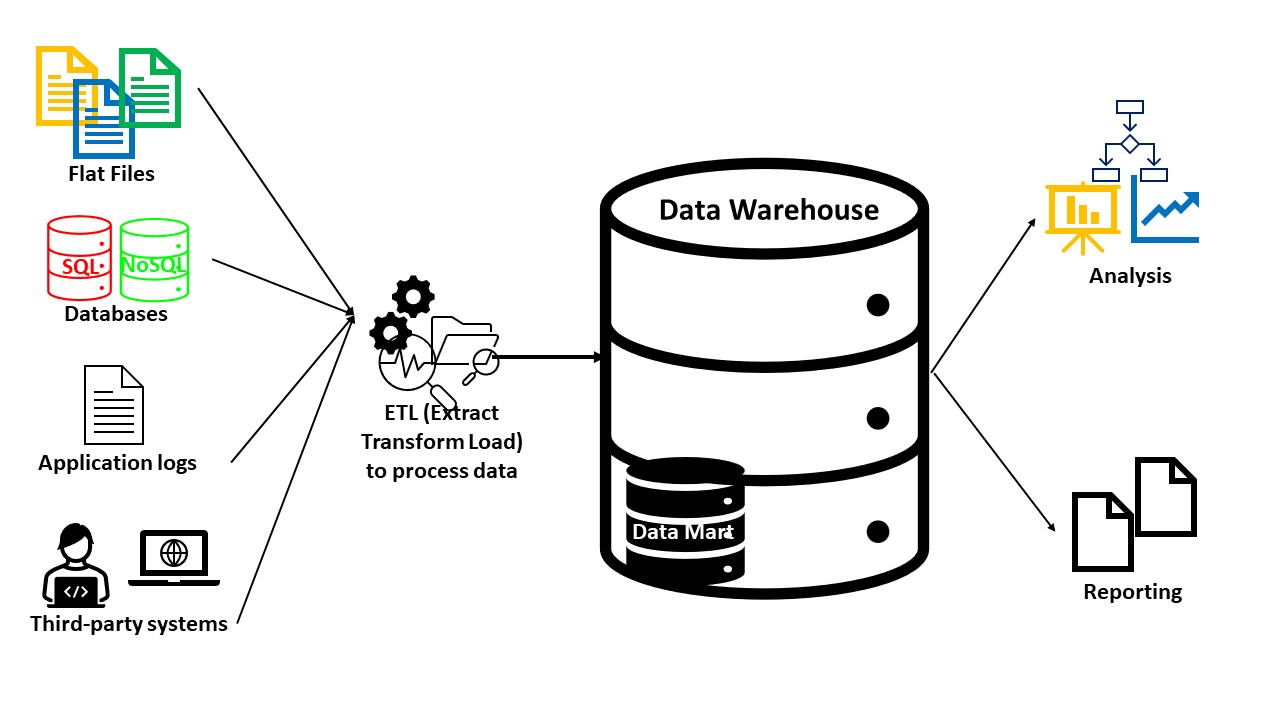
Another important point is that the data in the data warehouse comes from operational systems and sometimes from external sources. In other words, we are not creating data for the first time as part of a transaction such as the sale of a product, a stock movement or the hiring of an employee, these transactions take place and are recorded in various operational systems and then the data is sent to the data warehouse. We can say data warehouse is an usage and a database is a platform.
A data warehouse is not just a simple storage area where we store large amounts of data, there are some rules for how we should manage the data warehouse and how we should organize and store data.
In 1990, Bill Inmon set some rules for the data warehouse concept, these rules are that characteristics and functions of Data Warehouse should be Integrated, Subject Oriented, Time-Variant and Non-Volatile.
• The data warehouse is an integrated structure what that means is data from many different source streams is sent to the data warehouse.
• The data warehouse should be subject-oriented, no matter how much data comes from different sources.
• Data warehouses not only keep current data, but also historical data for the past.
• In general, data is loaded into the data warehouse as a "batch" at regular intervals. Data does not change in the data warehouse, even if millions of data changes between two uploads. Thanks to this, we can plan and make decisions using this data without constantly changing the data at hand.
What is the reason that we need a structure with these features?
We have two main reasons for establishing a data warehouse. First, to be able to make decisions based on data, rather than just making decisions with experience, intuition, or even hunches. The second is that many transactional and storage storage locations of data are all in one place for short periods of time, which is called “one stop shopping”.
When making data-driven decisions, we need to look to the past, the present, and even the future, or what we believe will likely be the future in various areas of our organization. And there is even a fourth step, which is usually called the unknown, where we don't ask specific job-related questions, but instead do a strong analytical study of a large amount of data and draw us an interesting and important inference from that data.
If we have the data that has all of these views in one place, we can say that we have the discipline we call Business Intelligence. There is a very strong relationship between business intelligence and data warehouse. The two concepts emerged around 1990, and these two concepts that work so well with each other have greatly increased the popularity of each other.
(geekflare.com/data-lake-vs-data-warehouse)
Data Warehouse Architecture
We have talked about most of the core features of the data warehouse, now let's take a look at what is the architectural options.
The first architecture that comes to mind is the Central Data Warehouse architecture.
In the central data warehouse structure, data from all sources are collected in a data warehouse built on a single database, and this data supports the Business Intelligence and Analytics side.
The concept of “one stop shopping” that we mentioned before is fully valid, so that all the data needed in reporting, business intelligence and analytics can be found in a single point.
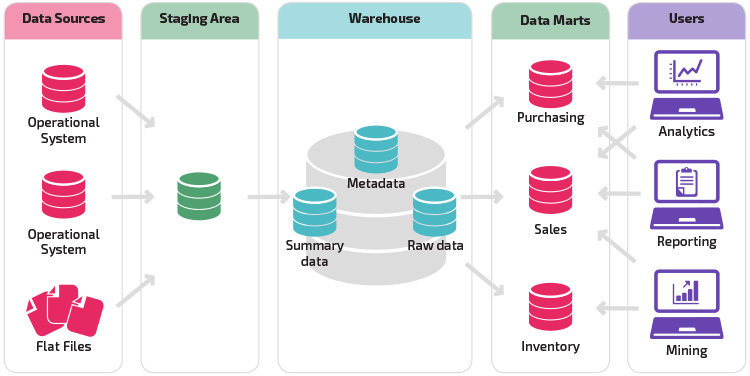
After the central data warehouse, the concept of Data mart comes to mind first. Data mart is a data warehouse on a smaller scale and more on a subject.
We can examine the data mart concept under two headings. First of all, we call data marts that are dependent on data marts that work depending on a data warehouse. Such data marts cannot survive without a data warehouse because they cannot be fed with data without a data warehouse. Secondly, data marts that do not need a data warehouse to maintain their continuity are called independent data marts. In independent data marts, each data mart is fed with data from one or more sources.
So what are the differences between a data warehouse and an independent data mart?
Actually there is not much difference between data warehouse and stand-alone data marts. The quickest feature that comes to mind is that today data warehouses can be fed from many sources in general, the number of different sources may be low, or there may be dozens, but independent data marts are usually fed from one or more sources. Another feature is that data mart keeps data focused on one subject, while data about multiple subjects can be kept in the data warehouse.
Considering the architectural options, you can choose a centralized, enterprise data warehouse architecture or a data lake architecture, or you can choose a component-based architecture, where the data warehouse and data marts work together.
(panoply.io/data-warehouse-guide/data-mart-vs-data-warehouse)
If you are wondering about what is the best architecture for you, you can contact us and explore Trendify solutions.
References
Alan Simon, Enterprise Business Intelligence and Data Warehousing: Program Management Essentials
